3. Dataset Construction
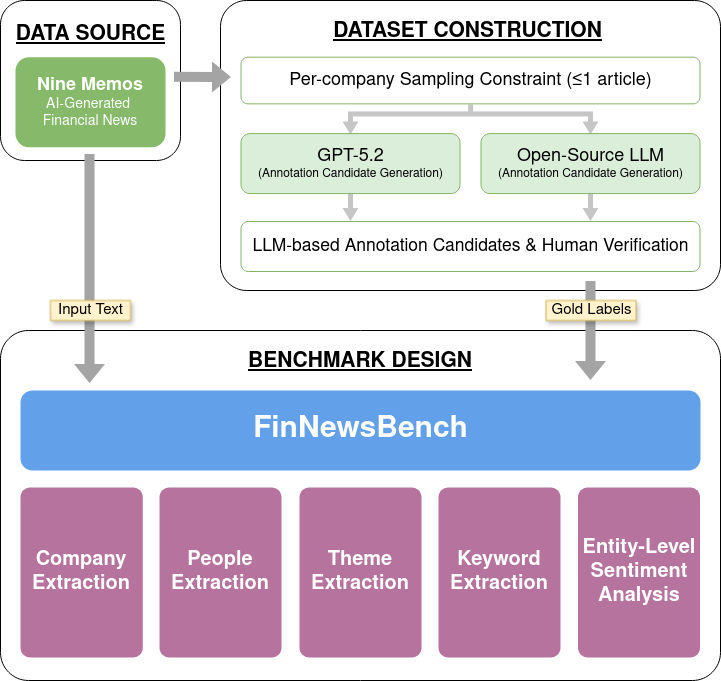
Figure 1. FinNewsBench dataset construction and annotation pipeline
3.1 Synthetic Financial News Source
FinNewsBench is designed to evaluate the structured information extraction capabilities of large language models from news text. For the construction of this benchmark, we utilize AI-generated Korean financial news provided by Nine Memos, a financial news service developed by 2Digit. The financial news articles from Nine Memos are generated in a format that summarizes and describes recent market trends, industry issues, and policy changes centered on specific company. As a result, each document densely contains information related to companies, people, themes, events, and sentiment. This structure closely resembles real-world investment information consumption environments while maintaining relatively consistent formats and clearly defined information units, making it well-suited as input data for an information extraction benchmark.
During dataset construction, news articles were selected to cover a wide range of companies and industries. To prevent overrepresentation of specific companies and mitigate the risk of models overfitting to company-specific expressions, the dataset includes a maximum of one news document per company. Specifically, we adopted the single primary company tag provided by Nine Memos for each article and included at most one article per tagged company. This design maintains a balanced distribution of samples across companies, enabling fair performance evaluation even in a non-trivial dataset setting and facilitating efficient comparison and analysis of multiple large language models.
As illustrated in Figure 2, the economic news articles within this benchmark dataset span 12 distinct industrial sectors based on the Global Industry Classification Standard (GICS). The dataset extensively represents major industry groups, particularly those with high visibility in economic reporting, such as Industrials (24.5%), Health Care(16.4%), Financials (12.4%), and Information Technology (12.3%). This composition effectively mirrors the data distribution found in real-world market environments, providing sufficient diversity to rigorously evaluate the generalizability of the model.
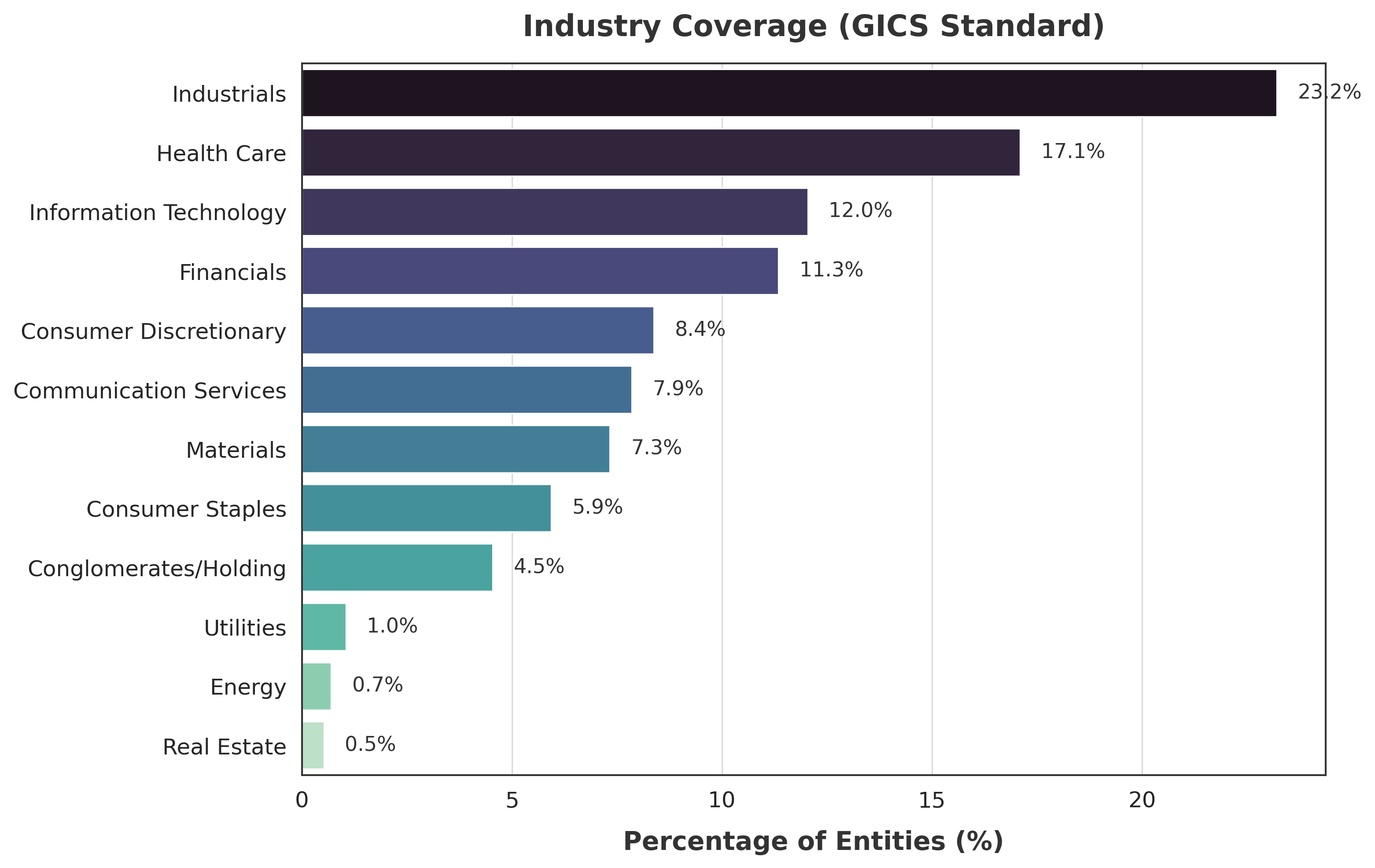
Figure 2. Distribution of Benchmark Entities by GICS Industrial Sector
3.2 Hybrid Labeling Pipeline
The reference annotations in FinNewsBench are constructed through a Hybrid Labeling Pipeline that combines LLM-based automatic extraction with human verification. This human-in-the-loop framework is designed to efficiently identify core metadata in generative financial news while incorporating domain-specific judgment criteria relevant to the financial sector.
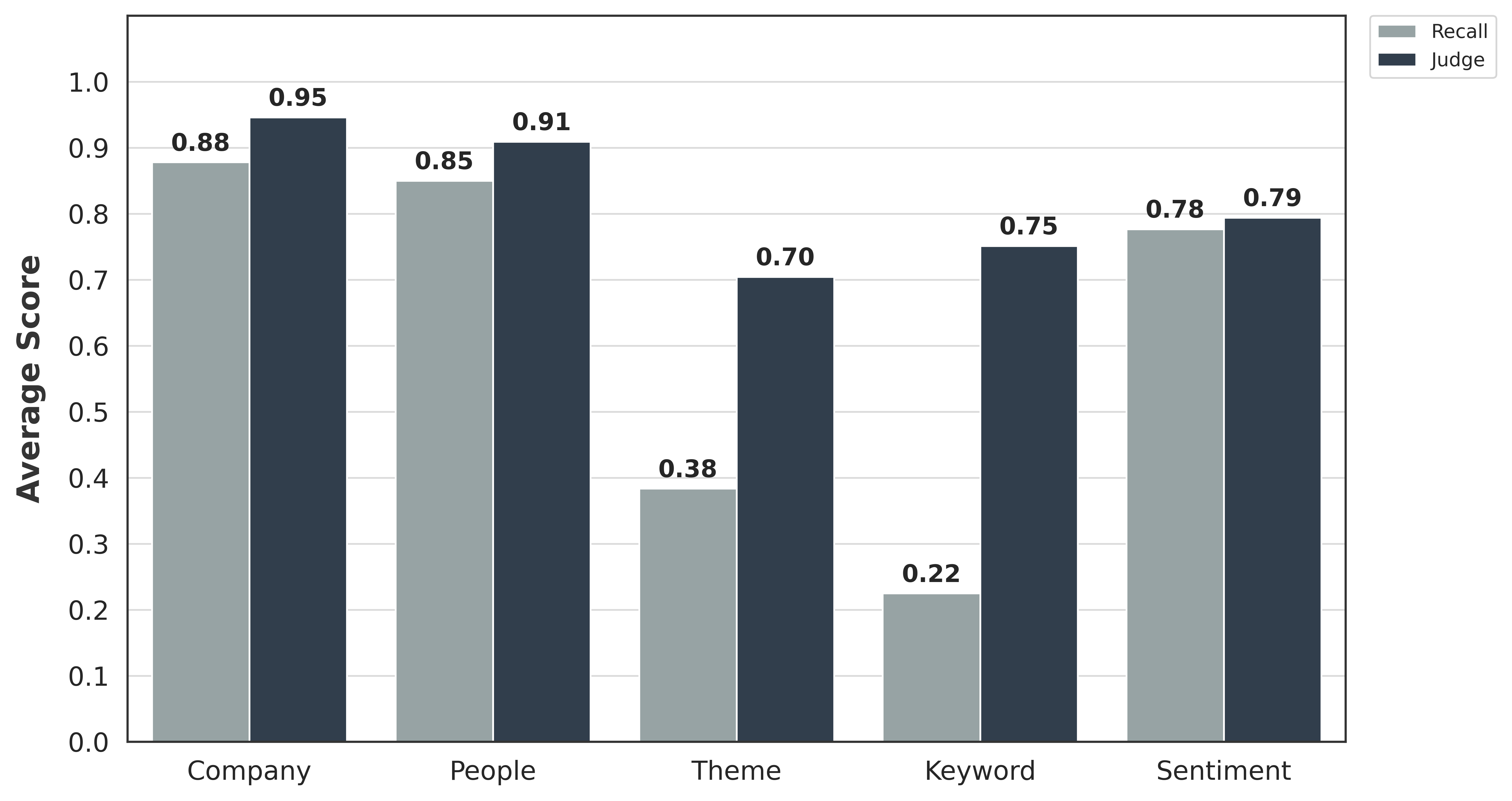
First, multiple LLMs—including GPT-5.2 and recent open-source models—are prompted to extract companies, people, themes, keywords, and central-company sentiment from each article. The outputs generated at this stage serve as initial annotation candidates, restricted to information explicitly mentioned in the news text. Candidate labels are first aggregated by taking the intersection of labels identified by multiple models. These candidate labels are then passed through GPT-5.2 to reassess their importance and reweight their relevance scores, producing a ranked set of salient, news-central entities. This step ensures that the final reference labels emphasize core information while remaining robust to variations and noise in initial model outputs.
Subsequently, expert human annotators review all candidate labels to correct misclassifications, remove irrelevant items, and adjust missing or excessive information. A category balancing procedure is also applied to mitigate distributional imbalances across entity types, ensuring more stable and fair model comparisons.
During this process, we acknowledge that the reference annotations are guiding signals rather than exhaustive ground truth lists. Due to annotation scope, ambiguity in financial narratives, or human oversight, some entities, themes, or keywords present in the article may not appear in the reference. Therefore, labels that are explicitly supported by the news text are considered valid, even if absent from the reference. This design principle allows the benchmark to focus on capturing news-central information while maintaining robustness to reasonable variations in candidate labels and human annotation decisions.
By integrating automatic extraction with human verification and incorporating this reference-augmented perspective, the Hybrid Labeling Pipeline produces high-quality gold-standard annotations that reflect both domain expertise and the open-ended, information-dense nature of financial news.
3.3 Dataset Statistics
FinNewsBench consists of 310 Korean financial news articles with moderate variation in length. As shown in Table 2, the average article length is 937 characters, with lengths ranging from 458 to 1,827 characters. This range provides sufficient contextual information for structured information extraction while avoiding extreme cases of overly short or excessively long documents.
| count | mean | min | max | std | |
|---|---|---|---|---|---|
| length | 310.00 | 937.14 | 458.00 | 1827.00 | 215.89 |
Table 2. Article Length Statistics of FinNewsBench
The density of annotated labels per article is summarized in Table 3. Each article contains a limited number of core entities, with an average of 2.2 company entities and 1.86 person entities, indicating that most news items focus on a small set of central actors. In contrast, semantic categories such as themes and keywords appear more frequently, reflecting the descriptive and multi-faceted nature of financial news. Sentiment annotations also exhibit a mixed distribution at the article level, with positive, negative, and neutral sentiment expressions co-occurring within individual articles. This highlights the nuanced and non-monolithic sentiment structure of financial news reporting. Notably, positive sentiment labels appear more frequently than negative or neutral ones in FinNewsBench. This skew can be partly attributed to the data source: the financial news articles are generated by an AI system used in the Nine Memos service, which is designed to summarize market trends, policy developments, and company-related outlooks for investment information delivery. As a result, the generated news tends to emphasize forward-looking perspectives, growth expectations, and interpretive context rather than purely adverse or incident-driven reporting, leading to a relatively higher prevalence of positive sentiment annotations.
| Avg per Article | |
|---|---|
| Company | 2.20 |
| People | 1.86 |
| Theme | 3.37 |
| Keyword | 7.55 |
| Positive | 1.95 |
| Negative | 0.65 |
| Neutral | 0.72 |
Table 3. Average Annotation Density per Article
As shown in Table 4, each theme is associated with a substantially large and diverse set of companies, with certain themes—most notably AI—linking several dozen distinct firms. This reflects the fact that the benchmark draws on financial news from 2025, a period characterized by intensified research, commercialization, and investment activity in AI-related industries. As a result, AI functions as a broad market-level investment narrative that spans multiple sectors rather than a narrow, article-specific topic.
This expanded many-to-many relationship between themes and companies further underscores that themes in FinNewsBench represent market-recognized constructs, reinforcing the need to identify news-central entities within each thematic context during annotation rather than treating themes as isolated topical labels.
| Theme | AI | 바이오 | 로봇 | 조선 | 반도체 | 방산 | 2차전지 | 우주항공 |
|---|---|---|---|---|---|---|---|---|
| Count | 57 | 30 | 19 | 18 | 16 | 16 | 13 | 13 |
Table 4. Number of Unique Companies per Theme