3. Dataset Construction
FinDartBench is a Korean financial QA benchmark built from disclosure documents collected from the Financial Supervisory Service’s electronic disclosure system (OpenDART). In this work, we used approximately 200 disclosure documents as source data, from which evaluation questions and reference answer candidates were automatically generated and progressively refined. The core objective of the construction process is not simply to mass-produce synthetic QA, but to build a highly reliable question–answer set suitable for practical evaluation.
The full construction process consists of three stages. First, the source disclosure documents are preprocessed, question candidates are generated for each document chunk, and semantically similar questions are consolidated into a representative question set. Next, multiple LLMs are used to generate answer candidates for each representative question. Finally, the generated answer candidates are sequentially filtered through factuality verification, Korean language quality evaluation, and consensus verification to finalize the reference answer set. Question and answer generation were carried out in a consistent manner using a vLLM-based serving environment with an OpenAI-compatible interface.
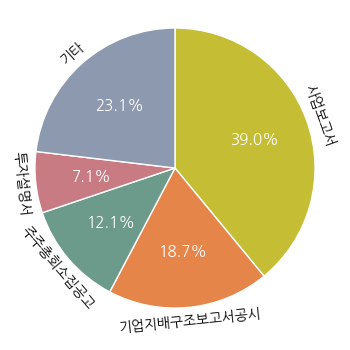
The source data consists of disclosure documents from 10 companies: LG Electronics, SK Telecom, Samsung Electronics, Hyundai Motor, Korea Electric Power Corporation, SK hynix, KB Kookmin Bank, HMM, Kia, and Dunamu. The document types include not only periodic disclosures such as annual and quarterly reports, but also various event-driven disclosures such as material event reports, corporate governance reports, and voluntary disclosures. As a result, FinDartBench is designed to evaluate not only financial numerical QA, but also understanding of diverse financial documents involving corporate governance, capital policy, related-party transactions, and shareholder meeting agenda items.
The overall construction pipeline is summarized in Figure 1.
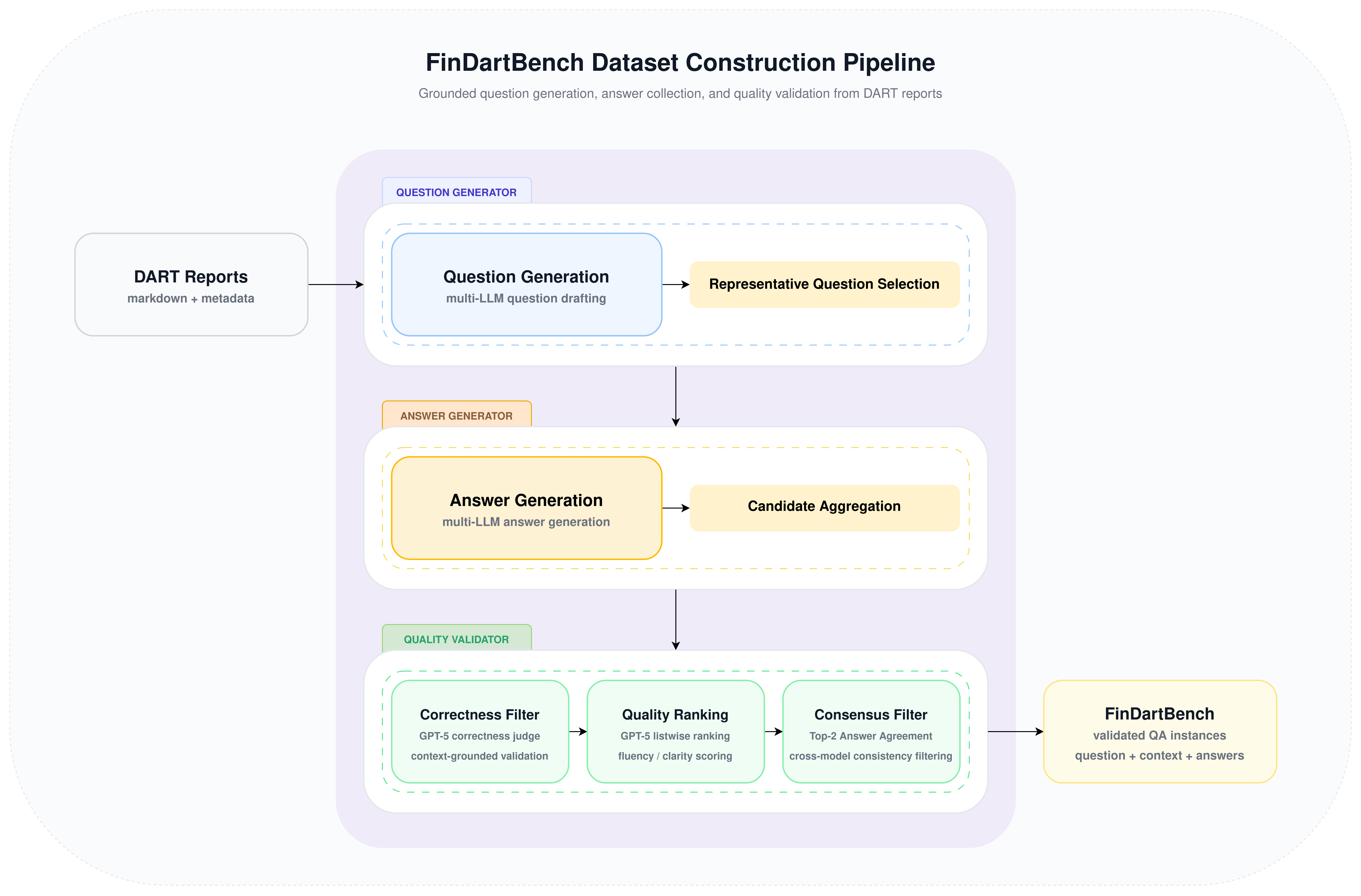
Figure 1. FinDartBench dataset construction pipeline
3.1 Question Generator
The Question Generator is the stage that produces question candidates from source disclosure documents and constructs a representative question set through deduplication. The goal of this stage is to secure a diverse set of questions grounded in document context while consolidating semantically equivalent questions into stable evaluation units. To achieve this, we first divide disclosure documents into input units suitable for question generation, then use multiple LLMs to generate structured QA candidates, and finally derive representative questions through similar-question clustering. For question generation and clustering, we used models such as Mistral-Large-3, GLM-4.7, and DeepSeek-V3.2-Exp.
In the preprocessing stage, company name and document-type metadata were extracted from document titles, and the body text was segmented according to the title hierarchy. Long sections were further split to remain within the maximum length constraint, while tables were processed in a way that preserved header and row structure to minimize information loss. In addition, when only a heading remained in isolation, it was re-merged with adjacent paragraphs to reduce semantic fragmentation. Each resulting chunk was augmented with the company name, document type, title information, chunk index, and total number of chunks, and then used as the basic unit for downstream question generation and traceability. Let the set of preprocessed document chunks be defined as $\mathcal{S} = \{ s_1, s_2, \dots, s_M \}$.
Question generation was performed using prompts that included few-shot examples. Given each chunk as input, the generation models were prompted to output a structured JSON list of QA pairs containing question_type, question, and answer. Here, the answer is not the final reference answer, but rather an initial draft used to check whether the generated question is appropriately grounded in the actual context. Based on this process, the initial question set is defined as
where $\mathrm{Gen}_Q$ denotes the multi-LLM-based question generation process.
To remove redundancy, the generated questions are clustered using their corresponding chunk context as auxiliary information. An LLM groups semantically identical or highly similar questions into clusters. Let the resulting cluster set be
$$ \mathcal{C}_Q = \{ C_1, C_2, \dots, C_K \}, \quad \bigcup_{k=1}^{K} C_k = \mathcal{Q}_0, \quad C_i \cap C_j = \emptyset, \quad i \neq j. $$For each cluster $C_k$, a representative question is generated as $q_k^{*} = \mathrm{Gen}_{\mathrm{repr}}(C_k)$, where $\mathrm{Gen}_{\mathrm{repr}}$ denotes the representative-question generation function that produces a single question capturing the core semantics of the cluster. The final representative question set is then defined as
$$ \mathcal{Q}^{*} = \{ q_1^{*}, q_2^{*}, \dots, q_K^{*} \}. $$Each representative question $q_k^{*}$ is paired with its corresponding source chunk $s_k \in \mathcal{S}$, inherited from the original generated-question instances in cluster $C_k$.
Through this process, the number of questions is reduced from 29,810 to 21,377, corresponding to a compression rate of 28.29%. The resulting representative question--context pairs are then used as input to the Answer Generator.
3.2 Answer Generator
The Answer Generator takes the representative questions produced during clustering, combines each question with its original document context, and collects candidate answers from multiple LLMs for each question. The purpose of this stage is to avoid reliance on a single model output and instead capture multiple perspectives and formulations for the same question, allowing more reliable reference answers to be selected in downstream verification.
For answer generation, we used a diverse set of models including Kimi-K2.5, Mistral-Large-3, GLM-4.7, and DeepSeek-V3.2-Exp. Each model independently generates an answer given the same question and its associated context, and the outputs are stored grouped by question. Formally, for each representative question $q_k^{*} \in \mathcal{Q}^{*}$ paired with its source chunk $s_k \in \mathcal{S}$, the set of candidate answers is defined as
$$ \mathcal{A}(q_k^{*}) = \{\, a_k^{(m)} \mid a_k^{(m)} = \mathrm{Gen}_A^{(m)}(q_k^{*}, s_k),\ m \in \mathcal{M} \,\}, $$where $\mathcal{M}$ denotes the set of answer generation models and $\mathrm{Gen}_A^{(m)}$ denotes the answer generation function of model $m$.
Each candidate answer includes both the model identifier and the answer text, and is later used as input to the Quality Validator for factuality verification and Korean language quality evaluation. This approach reduces model-specific bias and enables systematic comparison across multiple answer candidates for the same question.
3.3 Quality Validator
The Quality Validator selects the final reference answers from the pool of candidate answers generated by multiple models. While multi-LLM generation provides diverse candidates, these outputs are not directly suitable as evaluation references due to inconsistencies in factuality, expression quality, and conclusions. To address this, we construct a three-stage validation pipeline consisting of factuality verification, Korean language quality evaluation, and consensus verification.
For each representative question $q_k^{*}$ paired with its source chunk $s_k$, we apply staged validation to the candidate answer set $\mathcal{A}(q_k^{*})$ defined in Section 3.2. The goal of the Quality Validator is to transform this raw candidate pool into a validated reference answer set through staged filtering.
The first filtering stage is binary factuality verification. At this stage, $(q_k^{*}, s_k, a)$ is jointly provided as input, and each candidate answer $a \in \mathcal{A}(q_k^{*})$ is judged based on whether it satisfies the information need expressed by the question, whether its core facts, numbers, units, and temporal details are consistent with the context, and whether it avoids adding content not supported by the context. Let the binary factuality decision function be $\mathrm{Val}_{\mathrm{fact}}(q_k^{*}, s_k, a) \in \{0,1\}$. The factually valid candidate set is then defined as
$$ \mathcal{A}_{\mathrm{fact}}(q_k^{*}) = \left\{ a \in \mathcal{A}(q_k^{*}) \;\middle|\; \mathrm{Val}_{\mathrm{fact}}(q_k^{*}, s_k, a)=1 \right\}. $$Only candidates judged as correct are passed to the next stage, establishing a factual lower bound for the entire candidate pool.
The second stage performs listwise Korean language quality evaluation. Candidates that pass the first stage are jointly compared, ranked, and scored based on fluency, clarity, coherence, conciseness, and stylistic appropriateness. Let $\mathrm{Score}_{\mathrm{lang}}(q_k^{*}, s_k, a)$ denote the Korean language quality score assigned to candidate $a \in \mathcal{A}_{\mathrm{fact}}(q_k^{*})$. Given a predefined threshold $\tau$, the quality-filtered set is defined as
$$ \mathcal{A}_{\mathrm{lang}}(q_k^{*}) = \left\{ a \in \mathcal{A}_{\mathrm{fact}}(q_k^{*}) \;\middle|\; \mathrm{Score}_{\mathrm{lang}}(q_k^{*}, s_k, a) \ge \tau \right\}. $$This stage focuses on selecting the most natural and evaluation-suitable formulations among factually correct candidates, further removing low-quality expressions.
The third stage performs consensus verification. Let $a_k^{(1)}$ and $a_k^{(2)}$ denote the top-1 and top-2 answers in $\mathcal{A}_{\mathrm{lang}}(q_k^{*})$ sorted by $\mathrm{Score}_{\mathrm{lang}}$ in descending order. These two answers are compared to determine whether they convey the same conclusion and core content. Let the consensus decision function be
$$ \mathrm{Val}_{\mathrm{cons}}(q_k^{*}, s_k, a_k^{(1)}, a_k^{(2)}) \in \{0,1\}. $$A question is retained only if both high-quality candidates are available and the consensus decision is positive. Formally, the final retained question set is
$$ \mathcal{Q}_{\mathrm{final}} = \left\{ q_k^{*} \in \mathcal{Q}^{*} \mid |\mathcal{A}_{\mathrm{lang}}(q_k^{*})| \ge 2 \land \mathrm{Val}_{\mathrm{cons}}(q_k^{*}, s_k, a_k^{(1)}, a_k^{(2)}) = 1 \right\}. $$For each retained question $q_k^{*} \in \mathcal{Q}_{\mathrm{final}}$, the final validated answer set is defined as
$$ \mathcal{A}^{*}(q_k^{*}) = \mathrm{Sort}_{\mathrm{lang}}\!\left(\mathcal{A}_{\mathrm{lang}}(q_k^{*})\right), $$where $\mathrm{Sort}_{\mathrm{lang}}$ denotes sorting by Korean language quality score in descending order. Through this process, the number of questions is reduced from 19,537 to 14,444.
Although multi-LLM generation provides a large pool of candidate answers, these are not directly suitable as evaluation references due to inconsistencies in grounding and expression quality. The Quality Validator addresses this by progressively enforcing factual correctness, linguistic quality, and inter-candidate agreement, resulting in a high-reliability reference answer set suitable for evaluation.
The final dataset stores $(q_k^{*}, s_k, \mathcal{A}^{*}(q_k^{*}))$ for each retained question, where the validated answers are sorted by quality score and annotated with their source models.
{
"id": 1,
"doc_id": 1001,
"company": "HMM",
"doc_type": "사업보고서",
"context": "[입력 문서] ...",
"question": "2024 년 누적 연결기준 사업부문별 매출액 및 비중을 정리하시오.",
"answers": [
{
"model": "K-EXAONE-236B-A23B",
"answer": "..."
}
]
}